Large language models are impressive, but they lie. Not out of malice, but because their architecture is built on probability, not truth. When you ask an LLM to write a report, it predicts the next likely word, often stitching together plausible-sounding sentences that contain subtle factual errors. This phenomenon, known as hallucination, poses a critical risk for industries like healthcare, law, and finance. The solution isn't just better training data; it's robust online verification strategies that check facts in real-time or immediately after generation.
Evaluating factuality during generation has become one of the most active areas in AI research. Since the release of ChatGPT in late 2022, researchers have developed frameworks to catch these errors before they reach end-users. Today, we have sophisticated pipelines that can reduce factual errors by 40-60%. But implementing them correctly requires understanding the trade-offs between speed, cost, and accuracy. Let’s break down how these systems work, which tools are best for your needs, and what pitfalls to avoid.
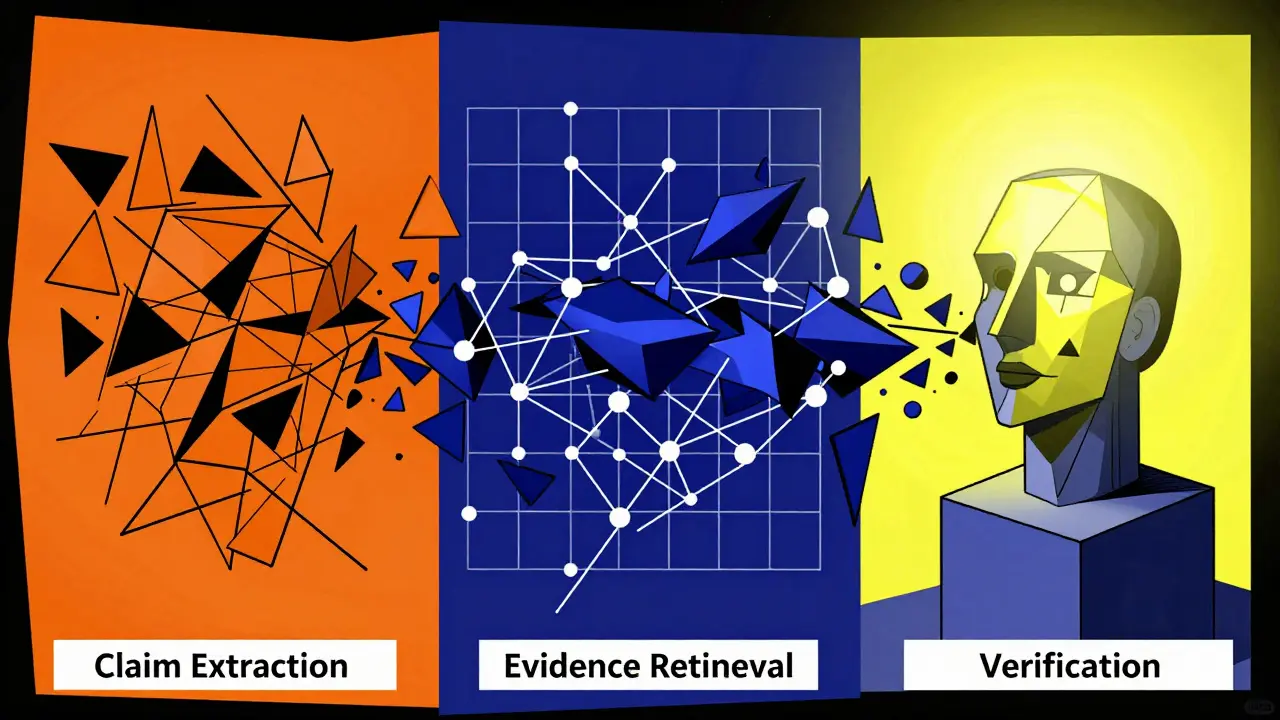
How Online Verification Works: The Three-Stage Pipeline
Most effective verification systems follow a standardized three-stage architecture. Understanding this flow helps you diagnose where failures occur in your own implementations.
- Claim Extraction: The system breaks down the generated text into atomic, context-independent claims. For example, if the LLM says "Paris is the capital of France and has a population of 2 million," the system extracts two separate claims: "Paris is the capital of France" and "Paris has a population of 2 million." State-of-the-art tools like FactScore achieve high precision here, though complex nested statements remain challenging.
- Evidence Retrieval: Each claim is used to search authoritative sources. This could be Wikipedia, verified news databases, or custom enterprise knowledge bases. Systems often combine traditional keyword search (BM25) with dense vector retrieval to maximize recall. High-performing setups achieve over 90% evidence recall on standard benchmarks.
- Verification: Finally, the system compares the claim against the retrieved evidence. This step uses either rule-based logic, natural language inference models, or another LLM acting as a judge. GPT-4-based verifiers currently lead in accuracy, scoring around 78.4% on comprehensive evaluation suites, but they come with significant latency and cost implications.
The bottleneck is usually the retrieval phase. If the system can’t find the right evidence, even the smartest verifier will fail. That’s why hybrid retrieval approaches-mixing BM25 and dense vectors-are becoming the industry standard, reducing false negatives by nearly 30%.
Top Frameworks Compared: OpenFactCheck vs. FactScore vs. Noblis G3
Choosing the right tool depends on your specific constraints: do you need raw accuracy, low latency, or easy integration? Here’s how the leading solutions stack up.
| Framework | Accuracy (Avg) | Latency per Claim | Cost per Verification | Best Use Case |
|---|---|---|---|---|
| OpenFactCheck | 81.7% | High (47 mins/doc) | Variable | R&D, Custom Pipelines |
| FactScore | 76.8% | Low (2.3 seconds) | Negligible | Production, High Volume |
| Noblis G3 | 85.2% | Medium | High Setup Cost | Enterprise, Govt, Technical Docs |
| Perplexity.ai | 72.1% | Very Low (1.8 seconds) | Subscription | Consumer Apps, Quick Checks |
OpenFactCheck, released by Stanford researchers in early 2024, is the most comprehensive framework. It integrates multiple modules (CustChecker, LLMEval, CheckerEval) and supports 14 different claim processors. It’s ideal for developers who need deep customization and are building new verification pipelines from scratch. However, it’s resource-heavy and takes time to set up.
In contrast, FactScore is the go-to for production environments where speed matters. It processes claims 3.2 times faster than OpenFactCheck with negligible API costs. You sacrifice some accuracy (around 5 percentage points lower), but for high-volume applications, the trade-off is often worth it.
For enterprise users dealing with proprietary data, Noblis G3 stands out. It uses a vector database approach tailored for technical documentation. While it achieves the highest accuracy (85.2%) in its niche, it requires extensive upfront curation-expect to spend 120+ hours setting up domain-specific knowledge bases.
Implementation Challenges: What Developers Actually Face
Reading benchmarks is easy; deploying these systems in production is hard. Based on feedback from developer communities and GitHub issues, here are the most common hurdles:
- Knowledge Base Configuration: 63% of users report this as "extremely difficult." Connecting custom enterprise data to retrieval engines often lacks clear documentation. You’ll need intermediate NLP skills to tune BM25 parameters and vector embeddings effectively.
- Latency Management: Real-time verification adds delay. 41% of production systems exceed acceptable response time thresholds when using heavy verifiers like GPT-4. A practical workaround is pre-filtering: only verify claims that fall below a certain confidence threshold, reducing load significantly.
- False Positives: Averaging 18.7% across implementations, false positives can frustrate users by flagging correct information as incorrect. Implementing claim confidence thresholds can reduce this rate by over 30%.
- Temporal Knowledge Gaps: Current systems struggle with time-sensitive claims. Accuracy drops by 32.6% on questions involving recent events or changing statistics. If your application relies on live data, standard verification may not suffice.
To mitigate these issues, many teams adopt a hybrid approach. They use lightweight extraction and retrieval for all content, then route only high-risk or low-confidence claims to expensive, high-accuracy verifiers. This balances cost and performance while maintaining trustworthiness.

Regulatory Pressures and Market Trends
The push for better factuality isn’t just technical-it’s regulatory. The EU’s AI Act, effective February 2025, mandates "appropriate technical measures" to mitigate risks of generating incorrect information in high-risk applications. This has accelerated adoption in financial services (42% of firms now use verification systems) and healthcare (37%).
The global market for LLM fact-checking technology is projected to hit $3.2 billion by 2026. We’re also seeing a shift toward real-time verification. Instead of checking outputs after generation, new architectures pause the LLM mid-generation to verify high-risk claims. This "self-verification" approach reduces final output errors by an additional 22.4%, according to recent MIT studies.
However, experts warn against over-reliance. Percy Liang, a computer science professor at Stanford, notes that current systems still miss 23.7% of subtle errors that human fact-checkers catch. Emily M. Bender from the University of Washington cautions that automated checkers inherit biases from their training data. These systems are scaffolds, not replacements for human oversight in critical contexts.
Future Directions: Self-Correction and Multi-Modal Verification
The field is moving fast. OpenFactCheck 2.0, released in January 2025, introduces optimized algorithms that cut latency by 3.8x. More importantly, researchers are exploring "self-correcting" paradigms where LLMs iteratively refine their own outputs based on internal verification signals. Early results show a 37.2% additional error reduction beyond standard methods.
Multi-modal verification is also on the horizon. As LLMs begin generating images and videos alongside text, frameworks like OpenFactCheck plan to support cross-modal fact-checking in Q2 2025. This will be crucial for combating misinformation in visual content.
Despite these advances, fundamental limits remain. Counterfactual reasoning tasks still see accuracy drop below 45% across all platforms. Until models develop true causal understanding rather than statistical pattern matching, human-in-the-loop verification will remain essential for high-stakes decisions.
What is the most accurate LLM factuality verification framework?
Currently, Noblis G3 achieves the highest accuracy at 85.2% for technical documentation, followed closely by OpenFactCheck at 81.7% across general benchmarks. However, Noblis G3 requires significant setup time for domain-specific knowledge bases, while OpenFactCheck offers more flexibility for diverse use cases.
How much does it cost to implement online verification?
Costs vary widely. FactScore has negligible API costs and is very affordable for high-volume use. In contrast, GPT-4-based verifiers like those in Factcheck-GPT can cost around $0.042 per verification, which adds up quickly. Enterprise solutions like Noblis G3 have high initial setup costs but lower marginal costs per query once configured.
Can these systems detect all types of hallucinations?
No. Current systems struggle with temporal knowledge (recent events), nuanced contextual statements, and counterfactual reasoning. Accuracy drops significantly for non-Western cultural topics and time-sensitive claims. They are best suited for verifying static, well-documented facts rather than complex interpretive statements.
Is real-time verification possible during generation?
Yes, emerging frameworks like OpenFactCheck 2.0 support real-time verification. This involves pausing the LLM during generation to verify high-risk claims before continuing. While this increases latency, it can reduce final output errors by an additional 22.4% compared to post-hoc checking alone.
Do I need a PhD in NLP to use these tools?
Not necessarily, but intermediate NLP knowledge helps. Tools like FactScore are designed for ease of use and work well out of the box. However, customizing retrieval pipelines or integrating with proprietary knowledge bases typically requires experience with vector databases, BM25 tuning, and API integration. Expect a 6-8 week learning curve for production-ready setups.